
Grafana
Composable dashboard platform that connects to 150+ data sources. Self-hosted under AGPL-3.0 or available as Grafana Cloud with a free tier.
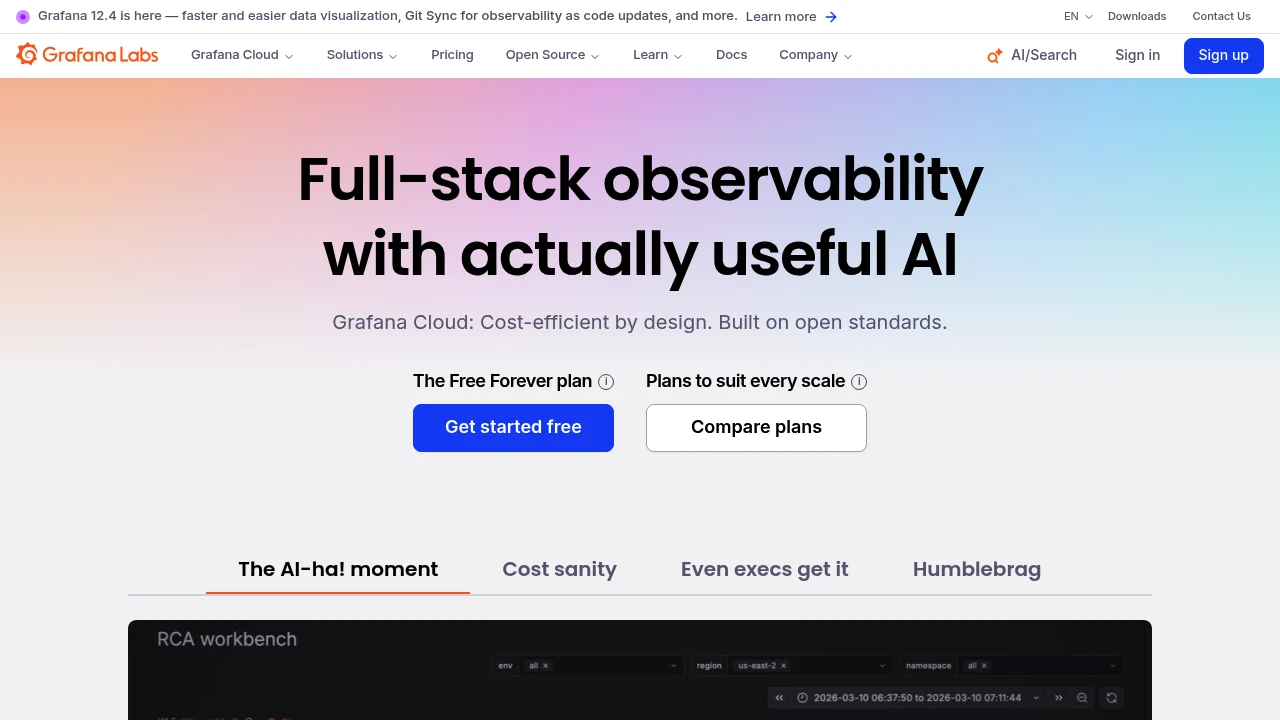
Most factories already collect data somewhere: a historian, a time-series database, an MQTT broker, a spreadsheet someone emails around. The hard part is getting that data onto a screen where it's useful. Grafana connects to wherever the data already lives and turns it into dashboards that operators, engineers, and managers can actually read. No ETL pipeline, no data warehouse project. Point it at InfluxDB, Prometheus, PostgreSQL, or any of 150+ supported sources and start building panels.
Key features
- 150+ data sources including InfluxDB, Prometheus, PostgreSQL, MySQL, Elasticsearch, Loki, Tempo, and cloud services like AWS CloudWatch and Azure Monitor
- Mixed-source dashboards that pull from multiple databases in a single view, so your OEE calculation can combine PLC data from InfluxDB with ERP data from PostgreSQL
- Alerting engine with support for multi-condition alerts, notification routing to email, Slack, PagerDuty, Microsoft Teams, and webhooks
- Templating and variables let one dashboard serve multiple production lines or machines by switching a dropdown
- Plugin ecosystem with community-built panels, data sources, and apps, including OPC-UA and MQTT plugins for industrial connectivity
- Annotations to mark events like shift changes, maintenance windows, or recipe changeovers directly on time-series graphs
- Dashboard provisioning via JSON or YAML files, enabling version-controlled dashboard-as-code deployments
What Grafana does
Grafana is a query and visualization frontend. It doesn't store data itself. You point it at one or more databases, write queries (or use the visual query builder), and arrange the results into panels on a dashboard. Panels can be graphs, gauges, tables, heatmaps, histograms, or any of dozens of visualization types.
The architecture is intentionally modular. Grafana handles the UI and query orchestration while your existing infrastructure handles storage. This means you can swap databases, add new data sources, or federate across sites without rebuilding dashboards from scratch.
In manufacturing, the most common deployment pattern is the MING stack: Mosquitto (MQTT broker) collects sensor data, Node-RED routes and transforms it, InfluxDB stores the time series, and Grafana visualizes everything. This combination gives you real-time OEE dashboards, energy monitoring, and production KPI tracking for $0 in software licensing.
For OPC-UA connectivity, there are community plugins (like the Simple OPC-UA data source) that let Grafana read directly from OPC-UA servers, though most production deployments route OPC-UA data through a collector like Telegraf or Kepware into a time-series database first.
Why choose Grafana
Zero licensing cost for self-hosted. The core Grafana OSS is AGPL-3.0 licensed. You can run it on a Raspberry Pi, a Docker container, or a Kubernetes cluster without paying anything. Grafana Cloud has a free tier (3 users, 10K metrics series, 50 GB logs) for smaller deployments.
You probably don't need to replace anything. Grafana connects to databases you already have. If your plant historian exports to PostgreSQL or your PLC data ends up in InfluxDB, Grafana works with what's there. No vendor lock-in to a proprietary data format.
Battle-tested scale. Grafana Labs reports over 800,000 active installations. The company has raised $791M in funding (last round $270M in August 2024), employs 1,700+ people across 40+ countries, and counts organizations across automotive, energy, food processing, and pharma among its users.
The ecosystem is enormous. With 73,000+ GitHub stars and nearly 3,000 contributors, Grafana has one of the largest open-source communities in the observability space. If you need a specific visualization or data source connector, someone has probably built it.
Getting started
Install Grafana OSS via Docker (docker run -d -p 3000:3000 grafana/grafana-oss), apt/yum on Linux, or Homebrew on macOS. First dashboard takes about 30 minutes if you already have a data source running. The visual query builder in recent versions reduces the learning curve for people who don't want to write PromQL or Flux.
The real investment is in dashboard design, not installation. Building a good OEE dashboard that covers availability, performance, and quality takes a few days of iteration. Grafana's public dashboard library has OEE templates you can import and customize. Companies like Factry and Enlyze offer pre-built manufacturing dashboard packages on top of Grafana for teams that want to skip the design phase.
For a single production line, one engineer with Docker experience can have a working MING stack in a day. Multi-site deployments with centralized dashboards, RBAC, and provisioned dashboard-as-code take more planning, but Grafana's Terraform provider and JSON provisioning system make it manageable without a dedicated platform team.
Technical specs
- Languages: Go backend, TypeScript/React frontend
- Deployment: Docker, Kubernetes (Helm chart), apt/yum packages, Windows installer, macOS Homebrew, or Grafana Cloud (managed SaaS)
- Minimum hardware: 1 CPU, 256 MB RAM (official minimum); production deployments typically use 2+ CPU, 4 GB RAM
- API: Full HTTP REST API for dashboard CRUD, data source management, user/org admin, and alerting
- Authentication: Built-in, LDAP, OAuth (Google, GitHub, Azure AD, Okta, generic), SAML (Enterprise)
- License: AGPL-3.0 (OSS), proprietary (Enterprise/Cloud)
Limitations
-
No built-in data storage. Grafana is purely a visualization layer. You need a separate database (InfluxDB, Prometheus, TimescaleDB, etc.) to store your time-series data. For teams without an existing database, this means deploying and maintaining an additional service.
-
Alerting can be frustrating. Grafana rewrote its alerting system (Unified Alerting replaced Legacy Alerting), and the transition left some rough edges. Complex alert rules with multiple conditions and notification policies have a steeper learning curve than tools with simpler built-in alerting.
-
Dashboard sprawl is real. Without governance, teams end up with dozens of overlapping dashboards that nobody maintains. Grafana doesn't enforce structure, so dashboard organization requires discipline and conventions. The provisioning system helps, but only if someone sets it up.
-
OPC-UA support is indirect. The official Grafana OPC-UA plugin reached end-of-life in 2024. Community plugins exist, but most production deployments still route industrial protocol data through a collector (Telegraf, Kepware, Node-RED) into a database rather than querying OPC-UA servers directly from Grafana.
-
Full-stack complexity. Running Grafana alone is simple. Running the full Grafana stack (Grafana + Loki for logs + Mimir for metrics + Tempo for traces) is a significant operational investment that typically requires Kubernetes expertise.
Integrates with
Grafana InfluxDB
InfluxDBGrafana reads from InfluxDB via Flux queries
Grafana Mosquitto
MosquittoGrafana subscribes to MQTT topics for real-time dashboards
 MalcolmGrafana
MalcolmGrafanaMalcolm's OpenSearch data can be visualized in Grafana as an alternative to OpenSearch Dashboards, integrating OT security alerts into existing plant monitoring dashboards.
 SuricataGrafana
SuricataGrafanaSuricata EVE JSON alert data can be visualized in Grafana via Elasticsearch or Loki, providing real-time security dashboards alongside OT metrics.

Similar to Grafana



